[R강의] 149. 벡터나 데이터프레임을 그룹별로 나눠 리스트에 저장 (split)
split 함수는 벡터나 데이터프레임을 그룹별로 나눠 리스트에 저장해주는 함수입니다. 어떻게 사용되는지 알아봅시다. 1. 벡터를 그룹별로 나눠 리스트에 저장 아래와 같은 벡터가 있다고 합시다. v=c(1,2,3,4,5,6,7,8,9) 각 값들은 아래와 같은 그룹에 속한다고 합시다. 그룹은 factor로 정의합니다. f=factor(c('A','A','B','A','A','B','A','A','B')) split 함수를 사용해봅시다. > split(v,f) $A [1] 1 2 4 5 7 8 $B [1] 3 6 9 2. 데이터프레임을 그룹별로 나눠 리스트에 저장 위에서 정의한 벡터와 요인으로 데이터프레임을 만들어봅시다. df=data.frame(v,f) > df v f 1 1 A 2 2 A 3 3 B 4 4..
2023. 3. 29.
 [R강의] 137. 데이터프레임 결합의 끝판왕 (merge)
merge 함수는 두 데이터프레임을 합쳐주는 함수입니다. rbind 보다는 cbind 와 유사한데요. cbind와 구벌되는 점은 특정 열을 기준으로 하여 합친다는 것입니다. 총 네가지 방법이 있는데요. 그림을 보면 쉽게 이해가 되실겁니다. 데이터프레임을 가지고 직접 해봅시다. 사용할 두 데이터는 아래와 같습니다. A=data.frame(id=c(1,2,3),weight=c(78,88,98),height=c(170,175,180)) B=data.frame(id=c(2,3,4),math=c(75,85,85),eng=c(100,85,60)) 콘솔창에 입력해보면 아래와 같습니다. > A id weight height 1 1 78 170 2 2 88 175 3 3 98 180 > B id math eng 1 2 ..
2023. 1. 31.
[R강의] 137. 데이터프레임 결합의 끝판왕 (merge)
merge 함수는 두 데이터프레임을 합쳐주는 함수입니다. rbind 보다는 cbind 와 유사한데요. cbind와 구벌되는 점은 특정 열을 기준으로 하여 합친다는 것입니다. 총 네가지 방법이 있는데요. 그림을 보면 쉽게 이해가 되실겁니다. 데이터프레임을 가지고 직접 해봅시다. 사용할 두 데이터는 아래와 같습니다. A=data.frame(id=c(1,2,3),weight=c(78,88,98),height=c(170,175,180)) B=data.frame(id=c(2,3,4),math=c(75,85,85),eng=c(100,85,60)) 콘솔창에 입력해보면 아래와 같습니다. > A id weight height 1 1 78 170 2 2 88 175 3 3 98 180 > B id math eng 1 2 ..
2023. 1. 31.
 [R강의] 133. 데이터프레임을 행으로 결합하기 (rbind)
데이터프레임을 행으로 결합하는 방법을 알아봅시다. 행으로 결합한다는 것은 아래와 같은 결합을 뜻합니다. 이때 rbind 함수가 사용됩니다. rbind 는 row(행) 을 bind(결합하다) 를 의미합니다. rbind 를 사용하려면 합치려는 데이터프레임들의 '열 이름'이 같아야 합니다. R코드로 예를 들어봅시다. 두개의 데이터 프레임을 생성합시다. A=data.frame(id=c(1,2,3), weight=c(78,88,98), height=c(170,175,180)) B=data.frame(id=c(4,5,6), weight=c(58,68,78), height=c(140,155,160)) 콘솔창에 출력해보면 아래와 같습니다. > A id weight height 1 1 78 170 2 2 88 175 3..
2023. 1. 24.
[R강의] 133. 데이터프레임을 행으로 결합하기 (rbind)
데이터프레임을 행으로 결합하는 방법을 알아봅시다. 행으로 결합한다는 것은 아래와 같은 결합을 뜻합니다. 이때 rbind 함수가 사용됩니다. rbind 는 row(행) 을 bind(결합하다) 를 의미합니다. rbind 를 사용하려면 합치려는 데이터프레임들의 '열 이름'이 같아야 합니다. R코드로 예를 들어봅시다. 두개의 데이터 프레임을 생성합시다. A=data.frame(id=c(1,2,3), weight=c(78,88,98), height=c(170,175,180)) B=data.frame(id=c(4,5,6), weight=c(58,68,78), height=c(140,155,160)) 콘솔창에 출력해보면 아래와 같습니다. > A id weight height 1 1 78 170 2 2 88 175 3..
2023. 1. 24.
[R강의] 132. 여러 점들 사이의 거리 한번에 구하는 법 (dist함수)
아래와 같이 5개의 점이 있다고 합시다. P1=c(1,2,3) P2=c(3,5,2) P3=c(5,5,4) P4=c(1,4,7) P5=c(2,2,4) 이들 중 어느 두 점이 가장 가까운 거리에 있는지 알고 싶은 상황입니다. 유클리드 거리를 행렬 형태로 출력해주는 함수가 있습니다. dist 함수입니다. 먼저 위 점들을 하나의 행렬로 묶어줍니다. mat1=matrix(c(P1,P2,P3,P4,P5),byrow=TRUE,nrow=5) > mat1 [,1] [,2] [,3] [1,] 1 2 3 [2,] 3 5 2 [3,] 5 5 4 [4,] 1 4 7 [5,] 2 2 4 위에서 만든 행렬에 dist 함수를 적용해봅시다. > dist(mat1) 1 2 3 4 2 3.741657 3 5.099020 2.828427 ..
2022. 12. 23.
 [하루만에 끝내는 R기초] 7교시. 조건문,반복문
지난시간에는 연산자를 배웠습니다. 연산자에는 산술, 비교, 논리연산자 있었는데요. 산술연산자와 비교연산자만 배웠습니다. 산술연산자는 사칙연산, 제곱과 같이 수학적인 연산을 말합니다. 비교연산은 크기를 비교하는 연산이고, 참 또는 거짓값을 반환합니다. 목차를 가져와서 오늘 배울 내용을 알아봅시다. 1교시) 강의 소개 2교시) R설치, R스튜디오 설치 3교시) 자료형 4교시) 변수 5교시) 자료구조 6교시) 연산자(산술,비교,논리) 7교시) 조건문, 반복문 8교시) 함수, 패키지 9교시) 그래프(박스플롯), t검정 10교시) 단축키 소개 및 전체요약 오늘 배울 내용은 조건문과 반복문입니다. '문'이라는 말이 붙어있는데요. 문장이라는 뜻입니다. 조건문은 조건이 들어있는 문장, 반복문은 반복이 들어있는 문장이라..
2022. 11. 12.
[하루만에 끝내는 R기초] 7교시. 조건문,반복문
지난시간에는 연산자를 배웠습니다. 연산자에는 산술, 비교, 논리연산자 있었는데요. 산술연산자와 비교연산자만 배웠습니다. 산술연산자는 사칙연산, 제곱과 같이 수학적인 연산을 말합니다. 비교연산은 크기를 비교하는 연산이고, 참 또는 거짓값을 반환합니다. 목차를 가져와서 오늘 배울 내용을 알아봅시다. 1교시) 강의 소개 2교시) R설치, R스튜디오 설치 3교시) 자료형 4교시) 변수 5교시) 자료구조 6교시) 연산자(산술,비교,논리) 7교시) 조건문, 반복문 8교시) 함수, 패키지 9교시) 그래프(박스플롯), t검정 10교시) 단축키 소개 및 전체요약 오늘 배울 내용은 조건문과 반복문입니다. '문'이라는 말이 붙어있는데요. 문장이라는 뜻입니다. 조건문은 조건이 들어있는 문장, 반복문은 반복이 들어있는 문장이라..
2022. 11. 12.
[R강의] 134. 여러 점들 사이의 코사인 거리 한번에 구하는 법 (dist함수)
아래와 같이 5개의 점이 있다고 합시다. P1=c(1,2,3) P2=c(3,5,2) P3=c(5,5,4) P4=c(1,4,7) P5=c(2,2,4) 이들 중 어느 두 점이 가장 가까운 거리에 있는지 알고 싶은 상황입니다. 일반적으로 알고 있는 유클리드 거리가 아닌 코사인 거리를 행렬 형태로 출력해보겠습니다. 코사인 각도는 원점과 각 점을 잇는 벡터들 사이 각도의 코사인 값입니다. 먼저 위 점들을 하나의 행렬로 묶어줍니다. mat1=matrix(c(P1,P2,P3,P4,P5),byrow=TRUE,nrow=5) > mat1 [,1] [,2] [,3] [1,] 1 2 3 [2,] 3 5 2 [3,] 5 5 4 [4,] 1 4 7 [5,] 2 2 4 코사인 거리를 계산할 때는 dist 함수에서 method 를 ..
2022. 2. 19.
 [R강의] 121. 축제거, 눈금제거, 축이름제거
그래프에서 축,눈금,축이름 제거하는 방법을 알아봅시다. 아래와 같이 정규분포 그래프를 하나 그리겠습니다. set.seed(999) x=seq(-4,4,0.01) y=dnorm(x) plot(x,y,type='l') 축,눈금, 축이름 제거 방법입니다. 주석으로 대신합니다. set.seed(999) x=seq(-4,4,0.01) y=dnorm(x) plot(x,y,type='l', axes=FALSE, #축제거거 xaxt='n', #x축 눈금 제거 yaxt='n', #y축 눈금 제거 ann=FALSE #축이름 제거 ) x축 이름 또는 y축 이름만 제거하기 원할 경우 아래 옵션을 사용합니다. xlab 또는 ylab에 ''을 입력하면 됩니다. 아래는 x축 이름만 제거한 예시입니다. set.seed(999) x=..
2021. 8. 13.
[R강의] 121. 축제거, 눈금제거, 축이름제거
그래프에서 축,눈금,축이름 제거하는 방법을 알아봅시다. 아래와 같이 정규분포 그래프를 하나 그리겠습니다. set.seed(999) x=seq(-4,4,0.01) y=dnorm(x) plot(x,y,type='l') 축,눈금, 축이름 제거 방법입니다. 주석으로 대신합니다. set.seed(999) x=seq(-4,4,0.01) y=dnorm(x) plot(x,y,type='l', axes=FALSE, #축제거거 xaxt='n', #x축 눈금 제거 yaxt='n', #y축 눈금 제거 ann=FALSE #축이름 제거 ) x축 이름 또는 y축 이름만 제거하기 원할 경우 아래 옵션을 사용합니다. xlab 또는 ylab에 ''을 입력하면 됩니다. 아래는 x축 이름만 제거한 예시입니다. set.seed(999) x=..
2021. 8. 13.
[R강의] 112. 상위 5개 숫자 추출하기
상위 5개 숫자를 출력하는 방법입니다. 설명은 주석으로 대신합니다. #데이터 A=c(1,4,23,5,2,122,3,7,2,65) #내림차순정렬 후 슬라이싱 A_top5=sort(A,decreasing = TRUE)[1:5]
2021. 5. 31.
R의 lapply 함수(리스트에 원하는 함수를 원하는 방향으로 적용)
lapply 함수는 리스트에 원하는 함수를 카테고리마다 적용해줍니다. 예를들어봅시다. 아래와 같은 데이터가 있습니다. 어떤 반의 인원이 다섯명이고, 다섯사람이 세과목의 시험을 본 결과 데이터입니다. > Math=c(94,82,45,55,67) > English=c(88,86,56,90,50) > Science=c(87,76,65,43,55) 리스트에 넣었습니다. > Li1=list(Math=Math,English=English,Science=Science) > Li1 $Math [1] 94 82 45 55 67 $English [1] 88 86 56 90 50 $Science [1] 87 76 65 43 55 laaply 함수를 적용해봅시다. 각 카테고리별로 평균이 구해지고, 결과가 리스트 형태로 출력됩..
2021. 3. 18.
R의 apply 함수(함수를 배열에 원하는 방향으로 적용)
apply 함수는 벡터,행렬,배열에 원하는 함수를 원하는 방향으로 적용해줍니다. 예를들어봅시다. 아래와 같은 데이터가 있습니다. 어떤 반의 인원이 다섯명이고, 다섯사람이 세과목의 시험을 본 결과 데이터입니다. > Math=c(94,82,45,55,67) > English=c(88,86,56,90,50) > Science=c(87,76,65,43,55) 데이터프레임에 넣었습니다. > DF1=data.frame(Math,English,Science) > DF1 Math English Science 1 94 88 87 2 82 86 76 3 45 56 65 4 55 90 43 5 67 50 55 apply 함수를 적용해봅시다. apply함수는 아래와 같은 형식으로 입력합니다. apply(데이터, 방향, 함수)..
2021. 3. 18.
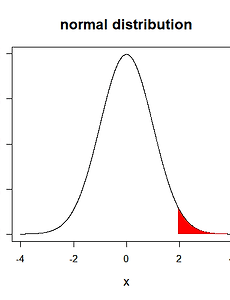 [R 강의] 94. 정규분포에 색칠하기
도구 R로 푸는 통계 94. 정규분포에 색칠하기 91강에서 배운 폴리곤 함수를 이용하여 정규분포 색칠을 하는 방법을 알아봅시다. 설명은 주석으로 대체합니다. ##정규분포 함수를 그리기 위한 데이터 생성 set.seed(2) x=seq(-4,4,0.001) y=dnorm(x) ##정규분포 함수 그리기 plot(x,y,type="l",ann=FALSE) title(main="normal distribution",xlab="x",ylab="f(x)", cex.lab=1.3,cex.main=1.5) ##색칠할 범위 설정하기 areaX=seq(1.96,4,0.01) areaY=dnorm(areaX) ##폴리곤 함수에 사용할 수 있도록 데이터 가공하기 xp=c(areaX,rev(areaX)) yp=c(rep(0,l..
2020. 6. 6.
[R 강의] 94. 정규분포에 색칠하기
도구 R로 푸는 통계 94. 정규분포에 색칠하기 91강에서 배운 폴리곤 함수를 이용하여 정규분포 색칠을 하는 방법을 알아봅시다. 설명은 주석으로 대체합니다. ##정규분포 함수를 그리기 위한 데이터 생성 set.seed(2) x=seq(-4,4,0.001) y=dnorm(x) ##정규분포 함수 그리기 plot(x,y,type="l",ann=FALSE) title(main="normal distribution",xlab="x",ylab="f(x)", cex.lab=1.3,cex.main=1.5) ##색칠할 범위 설정하기 areaX=seq(1.96,4,0.01) areaY=dnorm(areaX) ##폴리곤 함수에 사용할 수 있도록 데이터 가공하기 xp=c(areaX,rev(areaX)) yp=c(rep(0,l..
2020. 6. 6.














