[R 강의] 60. 객체의 내부 구조 보는 법 (str)
도구 R로 푸는 통계 60. 객체의 내부 구조 보는 법 (str) str 함수는 structure의 약어입니다. 벡터, 행렬, 리스트, 데이터프레임 등 객체의 '내부구조'를 보여줍니다. 내부를 한 눈에 볼 수 있어서 데이터프레임에 주로 사용됩니다. ex1) 벡터의 내부구조 보기 > a=c(1,2,3,4,5) > str(a) num [1:5] 1 2 3 4 5 ex2) 리스트의 내부구조 보기 > li=list(a=c(1,2,3),b=c("a","b","c")) > str(li) List of 2 $ a: num [1:3] 1 2 3 $ b: chr [1:3] "a" "b" "c" ex3) 데이터프레임의 내부구조 보기 > a=c(1,2,3) > b=c(1+1i,2+2i,3+3i) > c=c("a","b","..
2020. 3. 28.
[R 강의] 58. 데이터프레임 열추가, 행과 열에 이름 붙이기 (data.frame)
도구 R로 푸는 통계 58. 데이터프레임 열추가, 행과 열에 이름 붙이기 (data.frame) 데이터프레임을 하나 만들겠습니다. (데이터 프레임 만들기 : http://hsm-edu.tistory.com/481) 벡터를 먼저 정의하고 데이터프레임을 만들 수도 있지만, 아래와 같이 데이터 프레임 안에 직접 정의할 수도 있습니다. > DF=data.frame(a=c(1,2,3),b=c(1+1i,2+2i,3+3i),c=c("a","b","c")) > DF a b c 1 1 1+1i a 2 2 2+2i b 3 3 3+3i c 1. 데이터프레임에 열 추가하기 열을 추가하는 방법은 아래와 같습니다. d라는 열을 추가해보겠습니다. > DF$d=c(11,22,33) > DF a b c d 1 1 1+1i a 11 2..
2020. 3. 27.
[R 강의] 56. 데이터프레임 만들기 (data.frame)
도구 R로 푸는 통계 56. 데이터프레임 만들기 (data.frame) 데이터프레임은 R에서 가장 많이 사용되는 자료구조입니다. 데이터프레임의 형식은 행렬과 비슷한데, 모든 종류의 자료형을 동시에 담을 수 있습니다. (행렬 정의하기 : http://hsm-edu.tistory.com/406) 자료형에는 아래와 같은 종류가 있었습니다. (자료형 분류 : http://hsm-edu.tistory.com/314) - 숫자 (정수,실수,NaN,Inf) - NA(not available) - 복소수 - 문자열 - 논리값 - NULL - 요인(factor) 데이터프레임을 만드는 방법은 간단합니다. data.frame(자료,자료,자료,자료,...) ex1) 데이터프레임 만들기 > a=c(1,2,3) > b=c(1+1..
2020. 3. 27.
[R 강의] 55. 범주형 자료의 입력 (factor)
도구 R로 푸는 통계 55. 범주형 자료의 입력 (factor) 자료는 크게 둘로 나뉩니다. - 범주형자료(질적자료) - 연속형자료(양적자료) factor는 범주형 자료를 표현하기 위한 데이터타입(type)입니다. 범주형 자료는 순서가 있느냐 없느냐에 따라 명목척도, 순위척도로 나뉘는데요. 예를 들어보겠습니다. 범주형자료 - 명목척도 : 혈액형(A,B,O,AB), 남녀(M,F) - 순위척도 : 학년(1,2,3) factor를 입력하는 형식은 아래와 같습니다. factor(입력하기 원하는 데이터, 레벨, 순위여부) ex1) 혈액형 데이터 입력하기 친구 다섯명의 혈액형이 아래와 같다고 합시다. > bt=c("A","B","A","AB","O") factor로 입력해주겠습니다. > bt_f=factor(bt,..
2020. 3. 27.
[R 강의] 48. 분위수 구하는 방법 (quantile)
도구 R로 푸는 통계 48. 분위수 구하는 방법 (quantile) 분위수는 전체 자료를 등분할 때 기준이 되는 수 입니다. 분위수에 대한 자세한 설명은 아래 링크에서 보실 수 있습니다. (분위수 이론설명 : http://hsm-edu.tistory.com/533) R에서 제공하는 분위수 함수는 아래와 같습니다. quantile(x, probs = seq(0, 1, 0.25), type = 7) 자료를 입력하고, 자료를 나눌 비율을 정하고, 타입을 입력합니다. R에서는 분위수를 계산하는 type 9가지를 제공합니다. 각 방법에 대한 설명도 위 링크에 있습니다. 예를 들어봅시다. > a=c(24,28,37,43,46,47,59,67,75,77) > quantile(a) 0% 25% 50% 75% 100% ..
2020. 3. 25.
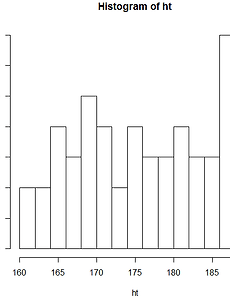 [R 강의] 45. 히스토그램 꾸미기
도구 R로 푸는 통계 45. 히스토그램 꾸미기 지난시간에는 히스토그램을 그려보았는데요. 오늘은 여러가지 옵션을 추가하여 히스토그램을 꾸며보겠습니다. 먼저 표본을 만들고 히스토그램을 그려봅시다. > ht=sample(160:190,50,replace=TRUE) > HT1=hist(ht, breaks=seq(160,190,2)) 1. 제목설정 제목을 설정하려면 main 옵션을 추가하면 됩니다. > HT1=hist(ht, breaks=seq(160,190,2), main="키_히스토그램") 2. x,y축 이름 설정 x,y 축 이름을 설정하려면 xlab과 ylab 옵션을 추가하면 됩니다. > HT1=hist(ht, breaks=seq(160,190,2), main="키_히스토그램",xlab="키",ylab="도..
2020. 3. 24.
[R 강의] 45. 히스토그램 꾸미기
도구 R로 푸는 통계 45. 히스토그램 꾸미기 지난시간에는 히스토그램을 그려보았는데요. 오늘은 여러가지 옵션을 추가하여 히스토그램을 꾸며보겠습니다. 먼저 표본을 만들고 히스토그램을 그려봅시다. > ht=sample(160:190,50,replace=TRUE) > HT1=hist(ht, breaks=seq(160,190,2)) 1. 제목설정 제목을 설정하려면 main 옵션을 추가하면 됩니다. > HT1=hist(ht, breaks=seq(160,190,2), main="키_히스토그램") 2. x,y축 이름 설정 x,y 축 이름을 설정하려면 xlab과 ylab 옵션을 추가하면 됩니다. > HT1=hist(ht, breaks=seq(160,190,2), main="키_히스토그램",xlab="키",ylab="도..
2020. 3. 24.
[R 강의] 43. 순서를 알려주는 함수 (rank)
도구 R로 푸는 통계 43. 순서를 알려주는 함수 (rank) rank 함수는 각 원소가 크기 순서로 몇위 인지를 반환해줍니다. 가장 작은 값이 1위입니다. > A=c(21,11,23,15,29,24,13) > rank(A) [1] 4 1 5 3 7 6 2 만약 같은 값이 있으면 어떻게 할까요. ties.method 라는 옵션을 사용해서 설정할 수 있습니다. 여섯가지 옵션중 하나를 설정할 수 있습니다. - average : 평균 순위로 설정 - first : 앞에 있는 원소를 높은 순위로 - last : 뒤에 있는 원소를 높은 순위로 - random : 임의로 - max : 두 순위 중 큰 값으로 - min : 두 순위 중 작은 값으로 예를 들어 설명하겠습니다. > A=c(1,2,3,3,4,5,6) > ..
2020. 3. 24.
[R 강의] 42. 중복 된 값을 다루는 함수 (unique, duplicated)
도구 R로 푸는 통계 42. 중복 된 값을 다루는 함수 (unique, duplicated) 1. unique 함수 unique 함수는 중복된 항을 하나만 남기고 제거해주는 함수입니다. > x=c(1,1,2,2,2,3,4,5) > unique(x) [1] 1 2 3 4 5 문자열에서도 가능합니다. > x=c('a','a','b','b','c','d','e','e') > unique(x) [1] "a" "b" "c" "d" "e" 2. duplicated 함수 duplicated 함수는 중복된 항에는 TRUE, 처음 등장하는항에는 FALSE를 반환해주는 함수입니다. > x=c(1,1,2,2,2,3,4,5) > duplicated(x) [1] FALSE TRUE FALSE TRUE TRUE FALSE FAL..
2020. 3. 23.
[R 강의] 41. 복제함수 (rep)
도구 R로 푸는 통계 41. 복제함수 (rep) rep는 복제함수입니다. replicate의 줄임 말입니다. 아래와 같이 사용합니다. rep(복제하기 원하는 스칼라 혹은 벡터, 복제 횟수와 방식) ex1) 2를 5번 복제 > rep(2,times=5) [1] 2 2 2 2 2 times를 생략하고 써도됩니다. > rep(2,5) [1] 2 2 2 2 2 ex2) 백터 (1,2,3)을 5번 복제 > rep(c(1,2,3),times=5) [1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 ex3) 벡터 (1,2,3)을 5번 복제하는데, 원소단위로 복제 > rep(c(1,2,3),each=5) [1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 each는 생략할 수 없습니다. 생략할 경우 ..
2020. 3. 23.
[R 강의] 40. 등차수열 생성함수 (seq함수)
도구 R로 푸는 통계 40. 등차수열 생성함수 (seq함수) seq함수는 '등차수열'을 생성해주는 함수입니다. 아래와 같은 형식으로 입력합니다. seq(시작,끝,간격 or 길이) 간격(or길이)를 입력해주지 않으면 default로 간격 1이 입력됩니다. ex1) 1~10의 범위와 간격1을 갖는 등차수열 > seq(from=1,to=10) [1] 1 2 3 4 5 6 7 8 9 10 아래와 같이 from, to를 생략해줄 수 있습니다. > seq(1,10) [1] 1 2 3 4 5 6 7 8 9 10 ex2) 1~10의 범위와 간격2를 갖는 등차수열 > seq(from=1,to=10,by=2) [1] 1 3 5 7 9 아래와 같이 from, to,by를 생략해줄 수 있습니다. > seq(1,10,2) [1..
2020. 3. 23.
[R 강의] 39. 모집단에서 표본 추출하기 (sample 함수)
도구 R로 푸는 통계 39. 모집단에서 표본 추출하기 (sample 함수) 1. sample(x,n) x라는 벡터에서 n개의 표본을 순서가 있게 뽑습니다. > sample(1:10,3) [1] 6 10 3 x를 입력하지 않으면 x에 1:n이 자동으로 입력됩니다. > sample(3) [1] 1 2 3 2. sample(x,n,replace=TRUE) x라는 벡터에서 중복을 허용하여 n개의 표본을 순서가 있게 뽑습니다. > sample(1:5,10,replace=TRUE) [1] 3 4 3 3 4 3 5 2 1 3 3. sample(x,n,prob=c(...)) x라는 벡터에서 중복을 허용하여 n개의 표본을 순서가 있게 뽑는데, 각 변수를 뽑는 확률을 지정해줍니다. > sample(c(1,2,3,4,5,6..
2020. 3. 23.
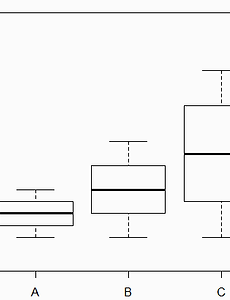 [R 강의] 38. Box Plot(상자그림)에 관측수, 표준편차 넣기
도구 R로 푸는 통계 38. Box Plot(상자그림)에 관측수, 표준편차 넣기 세 개의 데이터를 정의하고 boxplot을 그려봅시다. > a=c(1,2,3) > b=c(1,2,3,4,5) > c=c(1,2,3,4,5,6,7,8) > BP1=boxplot(a,b,c,ylim=c(0,10),names=c("A","B","C")) 1. 관측 수 넣기 text 함수를 이용하여 관측 수를 입력해줍니다. text(x좌표, y좌표, 텍스트) > text(1:3,BP1$stats[5,],paste("n=",BP1$n)) 위치를 나타내는 숫자 5를 1로 바꿔봅시다. 입력한 text를 바꾸고 싶으면, Boxplot을 다시 그려주어야 합니다. 그렇게 하지 않으면 text가 계속 누적되어 표시됩니다. > BP1=boxplo..
2020. 3. 22.
[R 강의] 38. Box Plot(상자그림)에 관측수, 표준편차 넣기
도구 R로 푸는 통계 38. Box Plot(상자그림)에 관측수, 표준편차 넣기 세 개의 데이터를 정의하고 boxplot을 그려봅시다. > a=c(1,2,3) > b=c(1,2,3,4,5) > c=c(1,2,3,4,5,6,7,8) > BP1=boxplot(a,b,c,ylim=c(0,10),names=c("A","B","C")) 1. 관측 수 넣기 text 함수를 이용하여 관측 수를 입력해줍니다. text(x좌표, y좌표, 텍스트) > text(1:3,BP1$stats[5,],paste("n=",BP1$n)) 위치를 나타내는 숫자 5를 1로 바꿔봅시다. 입력한 text를 바꾸고 싶으면, Boxplot을 다시 그려주어야 합니다. 그렇게 하지 않으면 text가 계속 누적되어 표시됩니다. > BP1=boxplo..
2020. 3. 22.
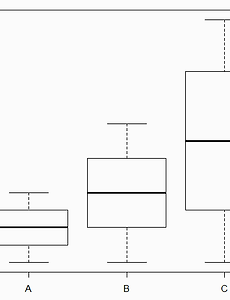 [R 강의] 37. Box Plot(상자그림) 내부 구조 뜯어보기
도구 R로 푸는 통계 37. Box Plot(상자그림) 내부 구조 뜯어보기 상자그림을 잘 다루기 위해 내부 구조를 이해할 필요가 있습니다. 다음 강의에서는 상자그림 안에 관측치와 표준편차를 입력할 것인데 내부 구조에 대한 이해가 필요합니다. 상자그림을 하나 만들어 봅시다. 옵션을 추가하지 않은 가장 기본적인 형태로 만들겠습니다. > a=c(1,2,3) > b=c(1,2,3,4,5) > c=c(1,2,3,4,5,6,7,8) > BP1=boxplot(a,b,c,names=c("A","B","C")) BP1을 입력해주면 내부 구조를 볼 수 있습니다. boxplot은 리스트 형태로 되어있다는 것을 알 수 있습니다. > BP1 $`stats` [,1] [,2] [,3] [1,] 1.0 1 1.0 [2,] 1.5 ..
2020. 3. 22.
[R 강의] 37. Box Plot(상자그림) 내부 구조 뜯어보기
도구 R로 푸는 통계 37. Box Plot(상자그림) 내부 구조 뜯어보기 상자그림을 잘 다루기 위해 내부 구조를 이해할 필요가 있습니다. 다음 강의에서는 상자그림 안에 관측치와 표준편차를 입력할 것인데 내부 구조에 대한 이해가 필요합니다. 상자그림을 하나 만들어 봅시다. 옵션을 추가하지 않은 가장 기본적인 형태로 만들겠습니다. > a=c(1,2,3) > b=c(1,2,3,4,5) > c=c(1,2,3,4,5,6,7,8) > BP1=boxplot(a,b,c,names=c("A","B","C")) BP1을 입력해주면 내부 구조를 볼 수 있습니다. boxplot은 리스트 형태로 되어있다는 것을 알 수 있습니다. > BP1 $`stats` [,1] [,2] [,3] [1,] 1.0 1 1.0 [2,] 1.5 ..
2020. 3. 22.
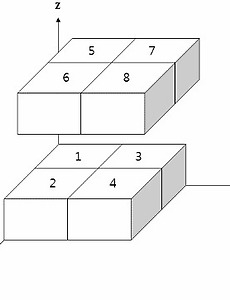 [R 강의] 36. 배열 데이터에 접근하기
도구 R로 푸는 통계 36. 배열 데이터에 접근하기 배열 데이터에 접근하는 방법을 알아봅시다. 1,2차원 배열은 스칼라와 행렬이므로 이미 다뤘습니다. 3차원 배열과 4차원배열을 예를 들어 설명하겠습니다. 1. 3차원 배열 내부 데이터 접근 3차원 배열을 하나 정의합시다. 2행,2열,2층으로 이루어진 배열입니다. > AB=array(1:8,dim=c(2,2,2)) > AB , , 1 [,1] [,2] [1,] 1 3 [2,] 2 4 , , 2 [,1] [,2] [1,] 5 7 [2,] 6 8 위 배열을 아래와 같이 공간에 나타낼 수 있습니다. dim=c(x,y,z) 로 해석한 것입니다. 접근하는 방식은 좌표를 입력해주듯 대괄호 안에 데이터의 위치를 입력해주면 됩니다. > AB[1,1,1] [1] 1 > A..
2020. 3. 22.
[R 강의] 36. 배열 데이터에 접근하기
도구 R로 푸는 통계 36. 배열 데이터에 접근하기 배열 데이터에 접근하는 방법을 알아봅시다. 1,2차원 배열은 스칼라와 행렬이므로 이미 다뤘습니다. 3차원 배열과 4차원배열을 예를 들어 설명하겠습니다. 1. 3차원 배열 내부 데이터 접근 3차원 배열을 하나 정의합시다. 2행,2열,2층으로 이루어진 배열입니다. > AB=array(1:8,dim=c(2,2,2)) > AB , , 1 [,1] [,2] [1,] 1 3 [2,] 2 4 , , 2 [,1] [,2] [1,] 5 7 [2,] 6 8 위 배열을 아래와 같이 공간에 나타낼 수 있습니다. dim=c(x,y,z) 로 해석한 것입니다. 접근하는 방식은 좌표를 입력해주듯 대괄호 안에 데이터의 위치를 입력해주면 됩니다. > AB[1,1,1] [1] 1 > A..
2020. 3. 22.
[R 강의] 34. 행렬의 결합
도구 R로 푸는 통계34. 행렬의 결합 r에서는 두개 이상의 행렬을 결합하는 함수를 제공합니다. 열 방향으로 결합하는 cbind와 행 방향으로 결합하는 rbind가 있습니다. 1. cbind (열 방향, 가로방향으로 결합) > a=matrix(c(1,2,3),ncol=1)> a [,1][1,] 1[2,] 2[3,] 3> b=matrix(c(4,5,6),ncol=1)> b [,1][1,] 4[2,] 5[3,] 6> c=matrix(c(7,8,9),ncol=1)> c [,1][1,] 7[2,] 8[3,] 9> cbind(a,b,c) [,1] [,2] [,3][1,] 1 4 7[2,] 2 5 8[3,] 3 6 9 2. rbind (행방향, 세로방향 결합) > a=matrix(c(1,2,3),nrow=1)> a..
2020. 3. 21.
[R 강의] 33. 행렬의 행과 열에 이름 붙이는 방법
도구 R로 푸는 통계33. 행렬의 행과 열에 이름 붙이는 방법 행렬에 이름을 붙이는 방법은 두 가지가 있습니다. 행렬 함수 안에 이름을 정의하는 방법은 27강에서 배웠습니다. 오늘은 이미 정의한 행렬에 이름을 붙이는 방법을 알아봅시다. 먼저 행렬을 하나 정의합시다. > A=matrix(c(1,2,3,4,5,6),ncol=2)> A [,1] [,2][1,] 1 4[2,] 2 5[3,] 3 6 rownames 함수를 사용하면 '행'의 이름을 붙여줄 수 있습니다. > rownames(A)=c("RN1","RN2","RN3")> A [,1] [,2]RN1 1 4RN2 2 5RN3 3 6 colnames 함수를 사용하면 '열'의 이름을 붙여줄 수 있습니다. > A CN1 CN2RN1 1 4RN2 2 5RN3 3 ..
2020. 3. 21.












