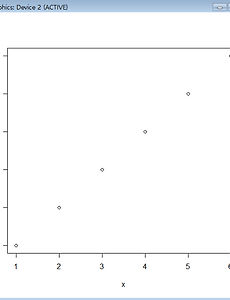
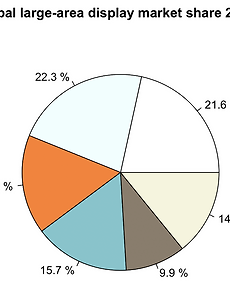
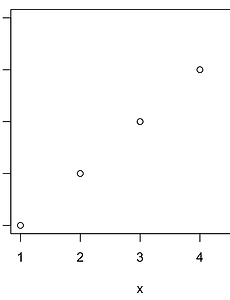
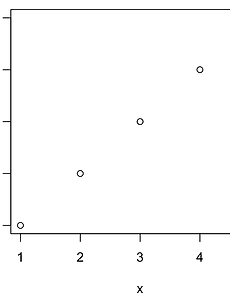
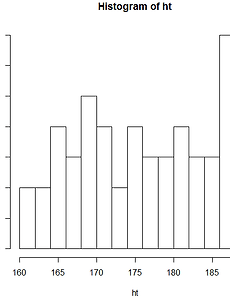
반응형 분류 전체보기464 [R 강의] 71. 산점도에서 점의 색 서로 다르게 설정하기 도구 R로 푸는 통계 71. 산점도에서 점의 색 서로 다르게 설정하기 먼저 산점도를 하나 그려봅시다. x=c(1,2,3,4,5,6) y=c(1,2,3,4,5,6) plot(x,y) 산점도의 색을 바꿔봅시다. col 옵션을 사용합니다. x=c(1,2,3,4,5,6) y=c(1,2,3,4,5,6) plot(x,y,col='red') 산점도에 색을 바꾸긴 했는데, 점마다 다른 색을 입력하고 싶은 상황입니다. 첫 두점은 빨간색, 나머지 네 점은 파란색으로 입력하려고 합니다. 이때는 col 옵션에 원소가 색으로 이루어진 벡터를 입력해주면 됩니다. x=c(1,2,3,4,5,6) y=c(1,2,3,4,5,6) plot(x,y,col=c('red','red','blue','blue','blue','blue')) 만약 .. 2020. 3. 31. [R 강의] 70. 파이그래프에 범례(legend) 추가하기 도구 R로 푸는 통계 70. 파이그래프에 범례(legend) 추가하기 68강에서 그렸던 파이그래프를 변형했습니다. 회사 이름을 빼고 퍼센트만 남겼습니다. 회사 이름은 오늘 배울 범례(legend)를 이용해서 나타내겠습니다. data= c(21.6,22.3,16.4,15.7,9.9,14.2) labels=paste(data,'%') mycolor=c(colors()[1],colors()[13],colors()[53],colors()[45],colors()[23],colors()[18]) title=c("Global large-area display market share 2017.1") pie(data,labels,col=mycolor,main=title) 위 그래프에 범례를 추가해봅시다. 회사 이름으로 .. 2020. 3. 30. [R 강의] 69. 문자열을 연결하는 paste 함수 paste 함수는 우리가 정의한 벡터의 원소에 무언가를 붙이거나 벡터의 원소를 하나로 합쳐주는 기능을 합니다. 설명만 들어서는 감이 안올 수 있으니 간단한 예제부터 시작해봅시다. > a=c(1,2,3,4,5) > paste(a) [1] "1" "2" "3" "4" "5" 아무 조건 없이 paste 함수를 적용하면, 우리가 정의한 벡터가 문자열 벡터로 변경됩니다. as.character 과 동일한 기능을 합니다. 일단 벡터를 문자열로 바꿔야 합치던지 다른 문자를 붙이던지 할 수 있기 때문입니다. 이번에는 모든 원소에 hi 라는 단어를 추가해보겠습니다. > a=c(1,2,3,4,5) > paste(a,"hi") [1] "1 hi" "2 hi" "3 hi" "4 hi" "5 hi" 기능이 이해가 되시나요? 이.. 2020. 3. 30. [R 강의] 68. 파이차트(원그래프) 그리는 방법 도구 R로 푸는 통계 68. 파이차트(원그래프) 그리는 방법 파이(pie)그래프를 그려봅시다. 파이(빵)를 잘라놓은 모양이어서 이런 이름이 붙었구요. 원그래프라고도 부릅니다. 파이그래프는 보통 전체에 대한 비율을 나타낼 때 사용합니다. 전체를 100%라고 했을 때, 각각이 차지하는 비율을 한 눈에 볼 수 있는 것이죠. 먼저 데이터를 하나 가져오겠습니다. 2017년 대형디스플레이 패널 점유율 데이터입니다. (출처 : IHS 마킷) LG디스플레이 : 21.6% BOE : 22.3% AOU : 16.4% Innolux : 15.7 Samsung Display : 9.9% Others : 14.2 % 데이터를 원소로 하는 벡터를 생성하고 가장 기본형태의 파이그래프를 그려보겠습니다. pie 함수를 사용합니다. d.. 2020. 3. 30. [R 강의] 67. 산점도 '점'의 모양 25가지 도구 R로 푸는 통계 67. 산점도 '점'의 모양 25가지 산점도를 꾸미는 방법을 이전에 다뤘었는데, 이번 강의에서는 점의 모양을 바꾸는 방법을 더 자세히 다루려고 합니다. 먼저 오늘 강의에 활용할 예시를 하나 만들어봅시다. > x=c(1,2,3)ㅁ > y=c(1,2,3) > plot(x,y) 점의 모양을 바꿔봅시다. 점의 모양은 pch=숫자 로 바꿉니다. cex=숫자 는 점의 크기입니다. 25가지의 모양을 전부 출력해봅시다. par함수를 이용하여 5x5 창을 만들고 for문을 이용하여 출력함수를 코딩하겠습니다. x=c(1,2,3) y=c(1,2,3) par(mfrow=c(5,5)) for (i in 1:25){ plot(x,y,pch=i,cex=3) } 아래와 같은 에러가 출력될 지도 모릅니다. 이때는.. 2020. 3. 30. [R 강의] 66. 산점도 '점'의 색 바꾸기 도구 R로 푸는 통계 66. 산점도 '점'의 색 바꾸기 산점도를 꾸미는 방법을 이전에 다뤘었는데, 이번 강의에서는 색을 바꾸는 방법을 더 자세히 다루려고 합니다. 먼저 오늘 강의에 활용할 예시를 하나 만들어봅시다. > x=c(1,2,3,4,5) > y=c(1,2,3,4,5) > plot(x,y) 점의 색을 바꿔봅시다. 색은 col='이름 or RGB or Hex color code' 옵션을 추가해주면 됩니다. 1. 이름으로 입력하기 점의 색을 이름으로 입력해봅시다. 어떤 색들을 제공하는지 궁금하신 분들은 R에 colors() 라고 입력하시면 색들을 보여줍니다. 3.5.1 버전 기준으로 무려 657가지나 제공합니다. > x=c(1,2,3,4,5) > y=c(1,2,3,4,5) > plot(x,y,col='.. 2020. 3. 29. [R 강의] 65. 균등분포 (uniform distribution) 도구 R로 푸는 통계 65. 균등분포 (uniform distribution) 균등분포는 확률밀도함수 값이 일정한 분포입니다. 균등분포와 관련된 함수는 네 가지가 있습니다. 1. 확률밀도함수 dunif(x, min = 0, max = 1, log = FALSE) 정의역이 0~5인 균등분포에서 3의 확률밀도 값을 구하겠습니다. > dunif(3,0,5) [1] 0.2 이번에는 log를 TRUE로 설정해서 구해보겠습니다. > dunif(3,0,5,log=TRUE) [1] -1.609438 0.2에 로그를 씌운 log(0.2)와 값이 동일합니다. > log(0.2) [1] -1.609438 2. 누적분포함수 punif(x, min = 0, max = 1, lower.tail = TRUE, log.p = FAL.. 2020. 3. 29. [R 강의] 64. 엑셀에서 저장한 CSV 파일 R로 불러오기 도구 R로 푸는 통계 64. 엑셀에서 저장한 CSV 파일 R로 불러오기 엑셀 시트에 데이터를 입력합시다. 아래 그림 처럼 10사람의 몸무게,키,나이라는 변수를 입력하겠습니다. 저장할 때, 파일 형식을 CSV로 바꿔줍니다. 이름은 excel_to_R 로 저장하겠습니다. R을 실행하고, 작업폴더를 CSV파일이 저장된 폴더로 바꿔줍니다. (작업 폴더 바꾸는 방법 : http://hsm-edu.tistory.com/477) > setwd("C:/Users/") read.csv 함수를 이용하여 엑셀에서 저장한 csv 파일을 열어줍니다. > my_csv=read.csv('excel_to_R.csv',header=FALSE) > my_csv V1 V2 V3 1 blood type height age 2 A 188 3.. 2020. 3. 29. [R 강의] 63. R에서 CSV 파일 저장하고 엑셀에서 열어보기 도구 R로 푸는 통계 63. R에서 CSV 파일 저장하고 엑셀에서 열어보기 1. 데이터를 CSV 파일로 저장하기 먼저 CSV 파일이 저장될 폴더를 작업폴더(working directory)로 설정해줍니다. (작업폴더 설정하는 방법 : http://hsm-edu.tistory.com/477) >setwd('C:/Users/Desktop/HSM') R 내장 데이터셋 중에서 trees를 CSV파일로 출력할 것입니다. trees는 데이터프레임입니다. 아래와 같이 my.trees에 trees를 저장해줍니다. > my.trees=trees > my.trees Girth Height Volume 1 8.3 70 10.3 2 8.6 65 10.3 3 8.8 63 10.2 4 10.5 72 16.4 5 10.7 81 1.. 2020. 3. 29. [R 강의] 62. order 함수 도구 R로 푸는 통계 62. order 함수 order 함수는 n번째 순위에 해당하는 원소가 원래 벡터에서 몇 번째 원소인지를 알려줍니다. 설명만으로는 이해가 어렵구요. 예제를 통해 이해해봅시다. > A=c(21,11,23,15,29,24,13) > order(A) [1] 2 7 4 1 3 6 5 order(A)에서 반환된 벡터의 첫번째 열에 입력된 값은 벡터 A에서 가장 작은 원소가 몇번째 원소인지를 알려줍니다. 2라는 것은 두번째 원소를 뜻하고 A벡터에서 11을 가리킵니다. 11이 벡터 A의 가장 작은 원소이기 때문입니다. 같은 원리로 두번째 열에 입력된 값은 벡터 A에서 두번째로 작은 원소가 몇번째 원소인지를 알려줍니다. 7번째 원소구요. 벡터 A의 7번째 원소는 13입니다. NA를 처리하는 방법은.. 2020. 3. 28. [R 강의] 61. 데이터가 너무 클 때 일부만 보여주는 함수 (head, tail) 도구 R로 푸는 통계 61. 데이터가 너무 클 때 일부만 보여주는 함수 (head, tail) 데이터 크기가 큰 경우에 일부 데이터만 출력해주는 함수가 head와 tail 입니다. head는 앞에서 부터, tail 은 뒤에서 부터 출력해줍니다. R에서 제공하는 내부 데이터셋 중 CO2로 예를 들겠습니다. 84행으로 이루어진 데이터프레임입니다. 1. head 함수 head 함수는 아래 형식으로 사용합니다. head(데이터, 보기 원하는 개수) > head(CO2,n=3) Plant Type Treatment conc uptake 1 Qn1 Quebec nonchilled 95 16.0 2 Qn1 Quebec nonchilled 175 30.4 3 Qn1 Quebec nonchilled 250 34.8 개수.. 2020. 3. 28. [R 강의] 60. 객체의 내부 구조 보는 법 (str) 도구 R로 푸는 통계 60. 객체의 내부 구조 보는 법 (str) str 함수는 structure의 약어입니다. 벡터, 행렬, 리스트, 데이터프레임 등 객체의 '내부구조'를 보여줍니다. 내부를 한 눈에 볼 수 있어서 데이터프레임에 주로 사용됩니다. ex1) 벡터의 내부구조 보기 > a=c(1,2,3,4,5) > str(a) num [1:5] 1 2 3 4 5 ex2) 리스트의 내부구조 보기 > li=list(a=c(1,2,3),b=c("a","b","c")) > str(li) List of 2 a:num[1:3]123 b: chr [1:3] "a" "b" "c" ex3) 데이터프레임의 내부구조 보기 > a=c(1,2,3) > b=c(1+1i,2+2i,3+3i) > c=c("a","b",".. 2020. 3. 28. [R 강의] 59. R에서 제공하는 내장 데이터셋(Dataset) 확인하는 방법 도구 R로 푸는 통계 59. R에서 제공하는 내장 데이터셋(Dataset) 확인하는 방법 R을 설치할 때 다양한 내장 데이터셋들도 함께 설치됩니다. 다양한 예제들이라고 보시면 됩니다. 이 데이터셋들은 R과 통계를 공부하는데 많은 도움이 됩니다. 데이터셋 목록을 불러오는 방법은 아래와 같습니다. > data() 새로운 윈도우 창에 데이터셋 목록이 출력됩니다. 왼쪽에는 데이터셋 이름이 있고 오른쪽에는 간단한 설명이 있습니다. 데이터셋 이름을 Console 창에 입력하면 저장된 데이터를 볼 수 있습니다. 이들중 첫번째 데이터셋을 불러와보겠습니다. > AirPassengers Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 1949 112 118 132 129 121 135.. 2020. 3. 28. [R 강의] 58. 데이터프레임 열추가, 행과 열에 이름 붙이기 (data.frame) 도구 R로 푸는 통계 58. 데이터프레임 열추가, 행과 열에 이름 붙이기 (data.frame) 데이터프레임을 하나 만들겠습니다. (데이터 프레임 만들기 : http://hsm-edu.tistory.com/481) 벡터를 먼저 정의하고 데이터프레임을 만들 수도 있지만, 아래와 같이 데이터 프레임 안에 직접 정의할 수도 있습니다. > DF=data.frame(a=c(1,2,3),b=c(1+1i,2+2i,3+3i),c=c("a","b","c")) > DF a b c 1 1 1+1i a 2 2 2+2i b 3 3 3+3i c 1. 데이터프레임에 열 추가하기 열을 추가하는 방법은 아래와 같습니다. d라는 열을 추가해보겠습니다. > DF$d=c(11,22,33) > DF a b c d 1 1 1+1i a 11 2.. 2020. 3. 27. [R 강의] 57. 데이터프레임에 접근하기 (data.frame) 도구 R로 푸는 통계 57. 데이터프레임에 접근하기 (data.frame) 데이터 프레임을 하나 정의하겠습니다. > a=c(1,2,3) > b=c(1+1i,2+2i,3+3i) > c=c("a","b","c") > DF=data.frame(a,b,c) > DF a b c 1 1 1+1i a 2 2 2+2i b 3 3 3+3i c 데이터 프레임에 접근하는 방법은 리스트와 동일합니다. 를이용해서접근합니다.>DFa [1] 1 2 3 > DFb[1]1+1i2+2i3+3i>DFc [1] a b c Levels: a b c 데이터프레임에 문자열 벡터를 입력했을 때, 자동으로 요인으로 인식한다는 것을 알 수 있습니다. 대괄호를 사용한 인덱싱도 가능합니다. > DF[1] a 1 1 2 2 3 3.. 2020. 3. 27. [R 강의] 56. 데이터프레임 만들기 (data.frame) 도구 R로 푸는 통계 56. 데이터프레임 만들기 (data.frame) 데이터프레임은 R에서 가장 많이 사용되는 자료구조입니다. 데이터프레임의 형식은 행렬과 비슷한데, 모든 종류의 자료형을 동시에 담을 수 있습니다. (행렬 정의하기 : http://hsm-edu.tistory.com/406) 자료형에는 아래와 같은 종류가 있었습니다. (자료형 분류 : http://hsm-edu.tistory.com/314) - 숫자 (정수,실수,NaN,Inf) - NA(not available) - 복소수 - 문자열 - 논리값 - NULL - 요인(factor) 데이터프레임을 만드는 방법은 간단합니다. data.frame(자료,자료,자료,자료,...) ex1) 데이터프레임 만들기 > a=c(1,2,3) > b=c(1+1.. 2020. 3. 27. [R 강의] 55. 범주형 자료의 입력 (factor) 도구 R로 푸는 통계 55. 범주형 자료의 입력 (factor) 자료는 크게 둘로 나뉩니다. - 범주형자료(질적자료) - 연속형자료(양적자료) factor는 범주형 자료를 표현하기 위한 데이터타입(type)입니다. 범주형 자료는 순서가 있느냐 없느냐에 따라 명목척도, 순위척도로 나뉘는데요. 예를 들어보겠습니다. 범주형자료 - 명목척도 : 혈액형(A,B,O,AB), 남녀(M,F) - 순위척도 : 학년(1,2,3) factor를 입력하는 형식은 아래와 같습니다. factor(입력하기 원하는 데이터, 레벨, 순위여부) ex1) 혈액형 데이터 입력하기 친구 다섯명의 혈액형이 아래와 같다고 합시다. > bt=c("A","B","A","AB","O") factor로 입력해주겠습니다. > bt_f=factor(bt,.. 2020. 3. 27. [R 강의] 54. 1표본 Z 검정 함수 만들기 도구 R로 푸는 통계 54. 1표본 Z 검정 함수 만들기 Z검정이 무엇인지 알고 있다고 가정하고 진행하겠습니다. Z검정이 궁금하신 분들은 아래 링크로 가셔서 보고오시면 됩니다. (1표본 Z검정의 원리 : http://hsm-edu.tistory.com/132) 1. 함수 만들기 코드를 추가해가며 순차적으로 진행하겠습니다. 한단계씩 따라하시면 됩니다. 1) R을 실행하고 새스크립트를 하나 열어줍니다. 방법을 모르시는 분은 아래 링크에서 보시면 됩니다. (함수를 파일로 저장하는 방법 : http://hsm-edu.tistory.com/478) 2) 함수 이름과 변수를 정해줍니다. 입력 변수는 표본평균, 표본 수, 모집단의 평균, 모집단의 표준편차입니다. my.z.test=function(sample_mean.. 2020. 3. 26. [R 강의] 53. 함수를 파일(.R)로 저장 및 사용하기 도구 R로 푸는 통계 53. 함수를 파일(.R)로 저장 및 사용하기 사용자가 정의한 함수를 파일로 저장해두고, 필요할 때마다 불러서 사용하는 방법입니다. 함수를 파일로 저장하기 위해서 새 스크립트를 하나 열어줍시다. 파일 → 새 스크립트 아래와 같이 R 편집기 화면이 뜹니다. 함수를 하나 정의하고 다른이름으로 저장합니다. 파일 이름은 my_mean.R 로 저장하겠습니다. 저장한 뒤에 R Console 창으로 돌아옵니다. 작업폴더를 함수가 있는 폴더로 설정해야 저장한 함수 사용할 수 있습니다. (작업폴더 설정/변경 : http://hsm-edu.tistory.com/477) > setwd("C:/Users/Desktop/R_MY_FUN") 함수를 사용하려면 먼저 함수를 실행해줘야 합니다. source함수를.. 2020. 3. 26. [R 강의] 52. 작업폴더 보기/설정하기, 작업폴더 내 파일보기 도구 R로 푸는 통계 52. 작업폴더 보기/설정하기 R에서 text 파일 등을 불러오거나 사용자가 만든 함수를 사용하려고 할 때, 작업폴더를 변경해야 할 경우가 있습니다. 1. 현재 작업폴더 확인하기 getwd() 함수를 사용합니다. 괄호 안은 비워두면 됩니다. > getwd() [1] "C:/Users/Documents" 2. 작업폴더 설정하기 setwd()함수를 사용합니다. 괄호 안에 경로를 넣어주시면 됩니다. setwd("C:/Users/Desktop/R_MY_FUN") 주의하실 점은 백슬레쉬 \가 아니라 / 슬레쉬를 사용한다는 것입니다. 속성에 들어가서 경로를 복사해서 붙여넣으신 뒤에 슬레쉬로 수정해야합니다. 3. 작업폴더 내 파일보기 dir() 함수를 사용합니다. 작업폴더 안에 들어있는 파일을 .. 2020. 3. 26. [R 강의] 51. 중심극한정리 시뮬레이션 도구 R로 푸는 통계 51. 중심극한정리 시뮬레이션 중심극한정리가 실제로 성립하는지 구현해봅시다. (중심극한정리 설명 : http://hsm-edu.tistory.com/21) 먼저 모집단을 만들겠습니다. 1~10,40~50,90~100 사이 수로 이루어진 집단입니다. Q-Q plot을 그려보면 정규분포를 따르지 않는다는 것을 알 수 있습니다. 의도적으로 정규분포를 따르지 않도록 설정하였습니다. (Q-Q plot 그리는 법 : http://hsm-edu.tistory.com/473) population=c(1:10,40:50,90:100) qqnorm(population) qqline(population) for문을 이용해서 표본을 3000번 뽑았습니다. 표본의 크기는 1부터 1000까지 증가시켰습니다... 2020. 3. 26. [R 강의] 50. 화면분할, 여러 그래프를 한 화면에 그리기 (par 함수) 도구 R로 푸는 통계 50. 화면분할, 여러 그래프를 한 화면에 그리기 (par 함수) 한 화면에 여러 그래프를 넣고 싶을 때가 있습니다. 이럴 때 사용하는 함수가 par 함수입니다. 아래와 같은 형식으로 사용하시면 됩니다. par(mfrow = c(x축 방향으로 분할 수, y축 방향으로 분할 수)) 4개의 히스토그램을 한 화면에 그려보겠습니다. (히스토그램 그리는 법 : http://hsm-edu.tistory.com/464) (히스토그램 꾸미는 법 : http://hsm-edu.tistory.com/465) 먼저 화면을 분할합시다. 2x2로 분할하겠습니다. > par(mfrow = c(2, 2)) 히스토그램 4개를 연속으로 그려주시면 됩니다. > ht=sample(160:190,50,replace=T.. 2020. 3. 25. [R 강의] 49. Q-Q plot 그리는 방법 (qqnorm) 도구 R로 푸는 통계 49. Q-Q plot 그리는 방법 (qqnorm) Q-Q plot은 Quantile-Quantile plot 의 약어입니다. Quantile은 '분위수'입니다. (분위수 설명 : http://hsm-edu.tistory.com/533) 이름 자체가 의미하고 있듯이 Q-Q plot은 분위수들을 그래프로 그리는 것입니다. 좌표평면에 있는 두개의 축에 서로 다른 두 데이터의 분위수를 각각 그려서 서로 비교합니다. 비교를 통해 두 데이터가 같은 분포를 따른는지 정성적인 판단을 합니다. 우리가 Q-Q plot을 사용할때는 주로 우리가 가진 데이터와 정규분포를 비교합니다. 따라서 '정규성 검정'의 한 방법이라고 이야기할 수도 있습니다. - 넓은 의미의 Q-Q plot : 임의의 두 데이터 분.. 2020. 3. 25. [R 강의] 48. 분위수 구하는 방법 (quantile) 도구 R로 푸는 통계 48. 분위수 구하는 방법 (quantile) 분위수는 전체 자료를 등분할 때 기준이 되는 수 입니다. 분위수에 대한 자세한 설명은 아래 링크에서 보실 수 있습니다. (분위수 이론설명 : http://hsm-edu.tistory.com/533) R에서 제공하는 분위수 함수는 아래와 같습니다. quantile(x, probs = seq(0, 1, 0.25), type = 7) 자료를 입력하고, 자료를 나눌 비율을 정하고, 타입을 입력합니다. R에서는 분위수를 계산하는 type 9가지를 제공합니다. 각 방법에 대한 설명도 위 링크에 있습니다. 예를 들어봅시다. > a=c(24,28,37,43,46,47,59,67,75,77) > quantile(a) 0% 25% 50% 75% 100% .. 2020. 3. 25. [R 강의] 47. 히스토그램에 도수 표시하기 도구 R로 푸는 통계 47. 히스토그램에 도수 표시하기 히스토그램에 도수를 표시할 때는 text 함수를 사용합니다. text함수 사용법에 대해서는 이전 강의에서 다뤘었습니다. text 함수 사용법(http://hsm-edu.tistory.com/456) 50개의 샘플을 뽑고 히스토그램을 그려봅시다. > ht=sample(160:190,50,replace=TRUE) > HT1=hist(ht) text 함수를 이용해서 도수를 표시합니다. > text(HT1mids,HT1counts+1,HT1counts)일부글자가잘리는것을알수있습니다.ylim을이용하여y축구간을넓혀줍시다.>HT1=hist(ht,ylim=c(0,16))>text(HT1mids,HT1counts+1,HT1co.. 2020. 3. 25. [R 강의] 46. 히스토그램 내부 구조 뜯어보기 도구 R로 푸는 통계 46. 히스토그램 내부 구조 뜯어보기 크기가 50인 표본을 하나 만들고 히스토그램을 그려봅시다. > ht=sample(160:190,50,replace=TRUE) > HT1=hist(ht) 표본 만드는 방법(http://hsm-edu.tistory.com/457) 히스토그램 내부를 보려면 아래와 같이 히스토그램 이름을 입력해주면 됩니다. > HT1 ‘breaks‘[1]160165170175180185190counts [1] 8 12 10 7 5 8 density[1]0.0320.0480.0400.0280.0200.032mids [1] 162.5 167.5 172.5 177.5 182.5 187.5 xname [1] "ht" equidist [.. 2020. 3. 24. [R 강의] 45. 히스토그램 꾸미기 도구 R로 푸는 통계 45. 히스토그램 꾸미기 지난시간에는 히스토그램을 그려보았는데요. 오늘은 여러가지 옵션을 추가하여 히스토그램을 꾸며보겠습니다. 먼저 표본을 만들고 히스토그램을 그려봅시다. > ht=sample(160:190,50,replace=TRUE) > HT1=hist(ht, breaks=seq(160,190,2)) 1. 제목설정 제목을 설정하려면 main 옵션을 추가하면 됩니다. > HT1=hist(ht, breaks=seq(160,190,2), main="키_히스토그램") 2. x,y축 이름 설정 x,y 축 이름을 설정하려면 xlab과 ylab 옵션을 추가하면 됩니다. > HT1=hist(ht, breaks=seq(160,190,2), main="키_히스토그램",xlab="키",ylab="도.. 2020. 3. 24. [R 강의] 44. 히스토그램 그리기 도구 R로 푸는 통계 44. 히스토그램 그리기 히스토그램을 그리기 위해 표본을 하나 만들어봅시다. 이전 강의에서 배운 sample 함수를 사용할 것이구요. 사람 키의 표본을 만들겠습니다. 160~190사이의 키를 가진 사람 50명을 뽑겠습니다. (표본 추출하는 방법 : http://hsm-edu.tistory.com/457) > ht=sample(160:190,50,replace=TRUE) > ht [1] 174 186 173 167 162 163 169 176 180 172 188 169 174 170 [15] 180 167 174 183 162 187 170 186 170 170 174 187 186 172 [29] 184 189 173 182 172 170 183 166 182 163 167 164.. 2020. 3. 24. [R 강의] 43. 순서를 알려주는 함수 (rank) 도구 R로 푸는 통계 43. 순서를 알려주는 함수 (rank) rank 함수는 각 원소가 크기 순서로 몇위 인지를 반환해줍니다. 가장 작은 값이 1위입니다. > A=c(21,11,23,15,29,24,13) > rank(A) [1] 4 1 5 3 7 6 2 만약 같은 값이 있으면 어떻게 할까요. ties.method 라는 옵션을 사용해서 설정할 수 있습니다. 여섯가지 옵션중 하나를 설정할 수 있습니다. - average : 평균 순위로 설정 - first : 앞에 있는 원소를 높은 순위로 - last : 뒤에 있는 원소를 높은 순위로 - random : 임의로 - max : 두 순위 중 큰 값으로 - min : 두 순위 중 작은 값으로 예를 들어 설명하겠습니다. > A=c(1,2,3,3,4,5,6) > .. 2020. 3. 24. [R 강의] 42. 중복 된 값을 다루는 함수 (unique, duplicated) 도구 R로 푸는 통계 42. 중복 된 값을 다루는 함수 (unique, duplicated) 1. unique 함수 unique 함수는 중복된 항을 하나만 남기고 제거해주는 함수입니다. > x=c(1,1,2,2,2,3,4,5) > unique(x) [1] 1 2 3 4 5 문자열에서도 가능합니다. > x=c('a','a','b','b','c','d','e','e') > unique(x) [1] "a" "b" "c" "d" "e" 2. duplicated 함수 duplicated 함수는 중복된 항에는 TRUE, 처음 등장하는항에는 FALSE를 반환해주는 함수입니다. > x=c(1,1,2,2,2,3,4,5) > duplicated(x) [1] FALSE TRUE FALSE TRUE TRUE FALSE FAL.. 2020. 3. 23. 이전 1 ··· 11 12 13 14 15 16 다음 반응형