반응형
[R 텍스트마이닝]
영화 어바웃타임 대본 단어 빈도분석 ⑤ 결과 분석하기
빈도를 계산한 결과를 분석해봅시다. 먼저 히스토그램을 그려봅시다. 이전 코드에 히스토그램을 그리는 코드추가하였습니다.
library(stringr)
library(dplyr)
#텍스트 불러오기
raw=readLines("E:/ONE_DRIVE/OneDrive/21.textmining/abouttime/abouttime.txt")
#불필요 기호 제거하기
raw2=raw %>% gsub(pattern=".",replacement="",fixed=TRUE) %>%
gsub(pattern="-",replacement="",fixed=TRUE) %>%
gsub(pattern="?",replacement="",fixed=TRUE) %>%
gsub(pattern=",",replacement="",fixed=TRUE)
#단어 단위로 쪼개기
word = strsplit(raw2 ,split=" ") %>% unlist()
word= tolower(word)
#불필요한 단어 찾아 위치 저장하기
rm_obj=which(!str_detect(word,"."))
#불필요한 단어 제거하기
word2=word[-rm_obj]
#빈도 계산하기
word_table=table(word2) %>% sort(decreasing=TRUE)
word_df=word_table %>% as.data.frame()
# 텍스트 파일 저장
write.table(word_df,file="abouttime_wordrank_final.txt",quote=FALSE)
#히스토그램
hist(word_table,breaks=seq(0,360,by=1))
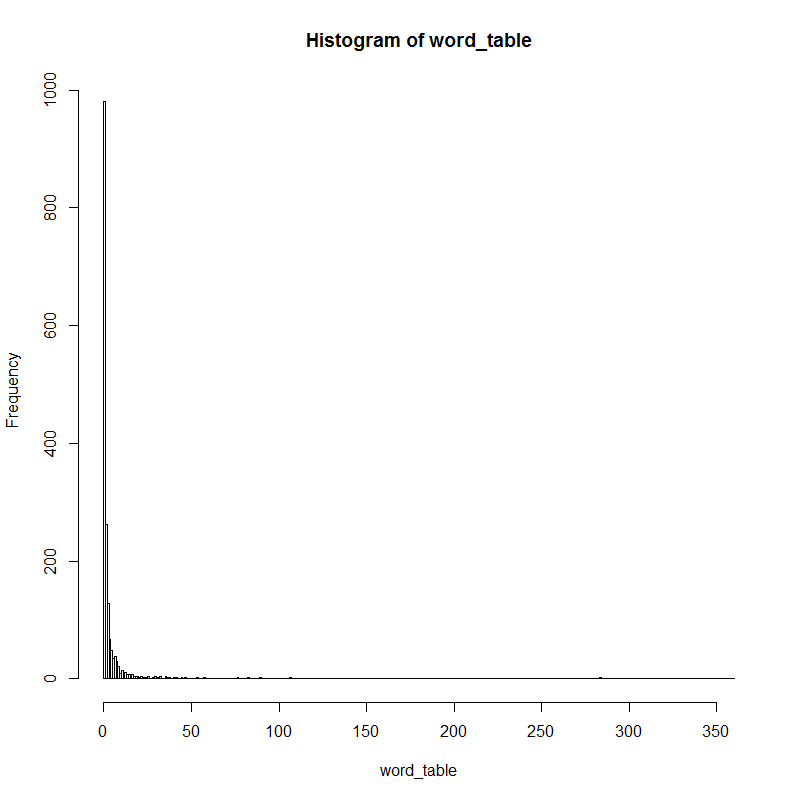
계급값을 확인해봅시다.
> myhist$breaks[1:10]
[1] 0 1 2 3 4 5 6 7 8 9
> myhist$counts[1:10]
[1] 980 262 129 67 48 34 38 29 21 9
전체 단어 1787개 중, 1번 등장하는 단어가 980개입니다. 1,2번 등장하는 단어가 전체 단어의 절반이 넘습니다.
경향을 파악하기 위해 단어의 누적 등장 빈도와 개수로 그래프를 다시 그려봅시다. 예를들어 x값이 10이라면, 10번 이상 등장하는 단어의 개수가 되는 것입니다. 히스토그램 코드를 아래와 같이 수정하면 됩니다.
#히스토그램
myhist=hist(word_table,breaks=seq(0,360,by=1))
cum=myhist$counts %>% rev %>% cumsum() %>% rev
cut=50
barplot(cum[1:cut],ylim=c(0,2000),names=myhist$breaks[-1][1:cut])

3번 이상 등장하는 단어의 수는 500개정도입니다. 영화에 나온 단어를 암기할 때, 빈도순으로 암기하기 원한다면 3번이상 등장하는 단어를 먼저 외우고 나서, 2번 1번으로 확장해가는게 좋을것 같습니다.
<어바웃타임 대본 단어분석>
전체 단어 수 : 1787개
1번 등장 단어 수 : 980개
2번 등장 단어 수 : 129개
3번 이상 등장 단어 수 : 545개
반응형
'R 주제 > 텍스트마이닝' 카테고리의 다른 글
| [R 텍스트마이닝] 영화 어바웃타임 대본 단어 빈도분석 ④ 소문자로 통일하기 (0) | 2020.12.07 |
|---|---|
| [R 텍스트마이닝] 영화 어바웃타임 대본 단어 빈도분석 ③ 빈 문자열 제거 (0) | 2020.12.07 |
| [R 텍스트마이닝] 영화 어바웃타임 대본 단어 빈도분석 ② 불필요한 기호 제거 (0) | 2020.12.04 |
| [R 텍스트마이닝] 영화 어바웃타임 대본 단어 빈도분석 ① 빈도분석 일단 해보기 (0) | 2020.12.04 |
| [R 텍스트마이닝] 창세기 단어구름(wordcloud) 만들기 (3) 단어구름 만들기 (0) | 2020.10.06 |
댓글